

Спасибо Данилу Шевченко — это он подкинул идею составить типологию морфинга глифов в нейросетях и описал некоторые характерные детали, на основе которых в дальнейшем можно разработать интересный проект настоящего шрифта. Похожие проекты, но без теоретизирования, приведены в этой статье.
Развитие генеративных нейросетей открыло новые возможности для создания изображений, включая тексты и буквы, без участия человека. Уже давно не секрет, что современные дизайнеры могут с помощью текстовых описаний получать «нейро-изображения» – от ии-фото до художественных иллюстраций и даже видео, – и часто такие изображения содержат текстовые элементы. Генеративный шрифт (Generative Font) — это тип шрифта, форма и стиль глифов которого создаются не вручную дизайнером «буква за буквой», а с помощью программного кода, алгоритмов или искусственного интеллекта. Строго говоря, шрифтом это называть нельзя. Это скорее «нейро-текст», визуальный почерк эпохи искусственного интеллекта: AI-модели воспроизводят буквы, но делают это не так, как традиционные шрифтовые программы или люди. Вместо аккуратных системных литер нейросети порой выдают искажённые надписи – с лишними штрихами, гибридными формами или совсем нечитабельный «шрифт» из абстрактных символов.
Тем не менее эти же ошибки и артефакты постепенно становятся дизайнерским ресурсом и инструментом для достижения различных коммуникационных целей, а чаще просто принимаются из-за нехватки бюджета или времени на доработку дизайн-макета. Цель данной статьи – исследовать, как нейросети генерируют буквы, какие специфические закономерности и артефакты при этом возникают, и как эти особенности могут быть осмысленно использованы дизайнерами. Также мы рассмотрим, понимают ли современные модели принципы шрифтов (строение графем, различие между латиницей и кириллицей и т.д.), и обсудим перспективы улучшения качества генерации текста: смогут ли нейросети в будущем создавать идеальные буквы без характерных искажений.
Генерация изображений с текстом: от первых моделей к современным
Создание осмысленного текста – одна из самых сложных задач для генеративных моделей изображений. Ранние системы вроде DALL-E, Stable Diffusion, Midjourney и др. применяли нейросетевые диффузионные модели для превращения текстового описания в картинку. Однако точное воспроизведение букв никогда не было их сильной стороной. Модели обучения ориентировались прежде всего на реалистичность и общую композицию изображения, поэтому текст воспринимался ими лишь как часть визуального шума или орнамента и узора, а не как знаковая система. Соответственно, попытки сгенерировать осмысленную надпись зачастую приводили к бессмысленному набору линий, отдалённо напоминающих буквы. Например, ранние версии Midjourney фокусировались на визуальных элементах и не уделяли внимания буквам – поэтому текст выходил как «бессмысленные каракули» вместо осмысленных слов.

Изображение, сгенерированное ранней версией Midjourney по промпту «generate a birthday card with the phrase 'Happy Birthday, Alex!' prominently displayed», Источник
Эта проблема во многом объясняется ограничениями обучающих данных: стандартные наборы изображений содержат относительно мало примеров чётко представленного текста (например, фото с чисто напечатанными надписями), поэтому модель просто не научилась писать разборчиво. В результате даже простое слово, запрошенное в prompt, могло превратиться в нечитаемый набор символов.
Почему же нейросети так трудятся над буквами? Дело в том, что генеративная модель не обладает врождённым пониманием алфавита – она оперирует статистическими образами. В отличие от человека, который знает, что слово состоит из определённых последовательных знаков, диффузионная сеть видит текст как картинку, как набор форм, а не как семантические символы. Малейшее искажение формы буквы, совершенно терпимое для объекта вроде пейзажа или животного, для текста оказывается фатальным: смещение черты или лишний изгиб делают букву неузнаваемой для нашего глаза.
Исследователи отмечают, что нейросети воспринимают буквы как визуальные текстуры, а не как знаки со строгими правилами, поэтому даже небольшое отклонение (например, слипшиеся или наложенные буквы, отсутствующая засечка) рушит читаемость слова. Человек мгновенно замечает любое отклонение от привычных очертаний букв, «спотыкается» и сталкивается с трудностями в чтении. Отсутствие буквального «понимания» текста у модели дополняется и особенностями обучения на ранних этапах: как правило, модели не обучались специально тонкостям типографики. Их задача – выдавать правдоподобную картинку в целом, а не точно соблюдать символы. Если размытая или изменённая буква не сильно портит общую эстетику изображения, модель легко «считает» такой результат приемлемым в функции потерь. У неё нет встроенной функции проверки орфографии или строгого контроля последовательности букв, как у человека. Поэтому ранние генеративные нейросети, даже обладая огромными параметрами, буквально не умели писать: вместо заданного слова «Truth» они выводили что-то вроде «Trutt» или «TURTH», стараясь лишь приблизительно воспроизвести образ слова, но не точные буквы.
Для практического дизайна такой «глючный» текст был бесполезен. Пользователям приходилось тратить время на постобработку: дорисовывать или заменять буквы вручную, что уменьшало профит от использования ИИ в подобных макетах. Таким образом, на ранних этапах генеративный текст в изображениях воспринимался скорее как раздражающий артефакт, чем как полезная функция.
Новое поколение моделей: решение «текстовой проблемы»
Ситуация начала меняться с появлением нового поколения моделей, в которых разработчики уделили особое внимание буквам. В 2023–2025 годах вышли системы, заявленные как умеющие генерировать чёткий и разборчивый текст прямо внутри изображения. К ним относятся, например, модель Gemini 3 Pro Image от Google (известная под кодовым названием Nano Banana Pro) и мультимодальные возможности GPT-4 от OpenAI (интегрированные в систему под названием Sora и GPT-4 Vision). В этих моделях нейросеть фактически совмещает навыки большой языковой модели и генератора изображений, что даёт неожиданно хороший эффект: модель знает, какие слова она должна вывести, и старается отобразить именно их. Так, OpenAI в марте 2025 года сообщала, что новая версия GPT-4 с генерацией изображений «превосходно точно воспроизводит текст», строго следуя заданным надписям. По сути, нейросеть впервые начала воспринимать текст внутри картинки не как абстрактный фон, а как семантически значимый объект, требующий точности.

Пример генерации текста в мультимодальной GPT-4o. Источник
У Google схожий подход: многомодальная система Gemini 3 способна генерировать постеры, диаграммы и даже переводы надписей на разные языки, сохраняя при этом высокую разборчивость шрифта. На официальной странице Gemini Image подчёркивается возможность «генерировать чёткий текст для плакатов… с последующим переводом дизайна под разные локализации». Ключевой упор – на резкость и читабельность букв: пользователь может описать даже тип шрифта или имитировать рукопись, и модель постарается это выполнить. Иными словами, новейшие генеративные сети начинают учитывать правила письма и формы букв, а не только общую картинку.
Стоит упомянуть и открытые разработки. Например, в 2023 г. компания Stability AI представила модель DeepFloyd IF, созданную специально для улучшенной генерации текста в изображениях. DeepFloyd IF – диффузионная модель, которую обучили на гигантском датасете (LAION-5B) с упором на английский текст. Разработчики заявили, что она превзошла предшественников по качеству надписей: IF генерирует высокодетализированные картинки и особенно хорошо справляется с текстом. По их словам, модель «научилась» вписывать заданные слова в изображение лучше, чем предыдущие открытые аналоги (Stable Diffusion и др.). Фактически, DeepFloyd IF продемонстрировала, что даже без проприетарных данных возможно добиться заметного прогресса – впервые опенсорсная модель могла надёжно генерировать читаемый текст в картинке.
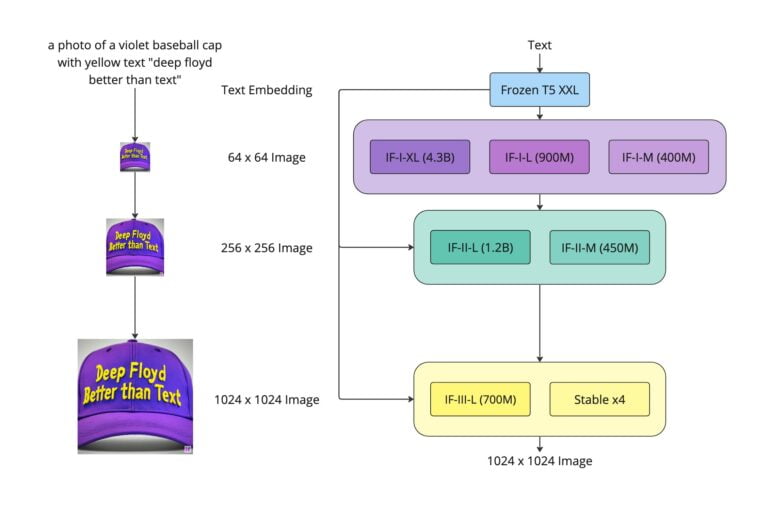
Архитектура IF похожа на архитектуру Imagen от Google. Источник
Новейшие коммерческие сервисы тоже идут в эту сторону. Появились специализированные генераторы изображений с текстом, например Ideogram (стартап выходцев из Google Brain) и Stockimg.ai Flux, которые рекламируют умение создавать логотипы и баннеры с чёткими надписями. Сравнение, проведённое компанией Stockimg, показало, что их модель способна выдать карточку с идеальной надписью «Happy Birthday, Alex!» (в отличие от Midjourney и прежнего DALL-E, где текст получался либо слишком замысловатым, либо размытым). Это подтверждает: проблема постепенно решается, и качество AI-генерации текста стремительно растёт.
Для иллюстрации возможностей современных моделей приведём пример изображения, сгенерированного Google Gemini (Nano Banana Pro). Здесь нейросети была дана сложная задача: изобразить скороговорку «How much wood would a woodchuck chuck if a woodchuck could chuck wood?», причём сами буквы должны быть выложены из брёвен, которые «набросал» бобр. Результат впечатляет: текст полностью читаем – каждая буква английского алфавита узнаваема и стоит на своём месте, фраза передана точно, а композиция выглядит осмысленно и декоративно.

Пример современного состояния: изображение, сгенерированное моделью Nano Banana Pro (Gemini 3) по запросу, где текст составлен объёмными буквами из брёвен – надпись хорошо читается и выполнена без ошибок, что свидетельствует о высоком качестве генерации. Источник
Таким образом, мы стоим на пороге нового этапа: генеративные нейросети начинают писать почти так же уверенно, как и рисовать. Это открывает перспективы для дизайнеров – от быстрого прототипирования афиш и логотипов до создания новых декоративных или акцидентных шрифтов. Однако прежде чем говорить о дизайне, рассмотрим ещё один аспект: а существуют ли модели, специально созданные для генерации шрифтов? И почему они пока не стали мейнстримом?
Специализированные модели генерации шрифтов и их ограничения
Помимо больших универсальных систем, генерирующих любые изображения, в последние годы велось немало исследований, направленных именно на создание новых шрифтов средствами ИИ. Такие проекты обычно фокусируются на том, чтобы по ограниченному набору символов автоматически достраивать полный шрифт в заданном стиле. Особенно актуальна эта задача для иероглифических систем (китайского, японского), где набор знаков огромен, и дизайнеру отрисовать тысячи символов вручную крайне трудоёмко. Нейросети предлагали решения: GAN-модели, сетевые автоэнкодеры и трансформеры, обученные на коллекциях шрифтов, научились генерировать отсутствующие буквы по нескольким образцам. К примеру, алгоритм DeepVecFont от Microsoft Research (2022) способен на основе нескольких нарисованных глифов выдавать остальные символы шрифта с сохранением стиля. Похожие подходы применялись для корейского алфавита (с учётом разделения слогов на компоненты), для рукописных латинских шрифтов и т.д.
Однако, несмотря на успехи в исследованиях, такие системы пока не получили широкого распространения среди практикующих шрифтовых дизайнеров. Причины во многом технические. Во-первых, многие модели работают с растрированными изображениями букв, а не с векторными кривыми. Итог их генерации – картинка символа, которую ещё нужно обводить кривыми вручную, чтобы превратить в полноценный шрифт. Такие растровые результаты не годятся прямо для индустрии шрифтов. Современный шрифт – это набор цифровых векторных контуров, а не пикселей, поэтому дизайнеру пришлось бы фактически заново отрисовать полученные буквы. Во-вторых, ранние алгоритмы грешили несогласованностью форм: сгенерированный набор букв мог выглядеть интересно, но между собой буквы не сочетались идеально, требовали выравнивания оптических размеров, корректировки просветов и т.д. То есть без ручной доработки не обходилось.
Тем не менее движение в эту сторону есть. В 2023 году на рынке появились онлайн-сервисы – своего рода «ии-шрифтовики» – которые обещают быстро создавать оригинальные шрифты на основе текстовых запросов или парочки референсных гарнитур. К ним относятся, например, инструменты в платформах вроде Simplified, Fontjoy AI, Adobe Firefly (генерация стилей) и др. Они комбинируют машинное обучение с классическими принципами типографики, позволяя пользователю задавать описание («ретро-футуристический жирный шрифт», «рукописный остроугольный» и т.п.), на основе которого нейросеть предлагает несколько вариантов гарнитур. Под капотом у таких сервисов – либо предварительно обученные на тысячах шрифтов трансформеры, либо GAN, умеющий плавно интерполировать между разными шрифтами. Получившийся шрифт обычно можно сразу скачать (в виде шрифтового файла) или использовать в дизайне.
Однако качество и удобство этих генераторов пока ограничено. Чаще всего они годятся для поиска идей, набросков стиля, но не для выпуска готового шрифта без ручной шлифовки. Кроме того, возникает юридический вопрос оригинальности: обученные на существующих гарнитурах нейросети могут неосознанно воспроизводить элементы дизайна, защитить которые авторским правом проблематично. Наконец, многие шрифтовые AI-модели пока требуют серьёзных вычислительных ресурсов или времени на генерацию, что снижает их привлекательность в ежедневной работе. Поэтому профессиональные шрифтовики относятся к ИИ-инструментам пока осторожно. Сами же исследователи подчёркивают, что ИИ в типографике – лишь вспомогательный «напарник» дизайнера, а не замена ему . Автоматизация рутинных операций (дорисовка недостающих символов, интерполяция между начертаниями) – вот наиболее реалистичная ниша применения нейросетей в шрифтовом производстве на текущий момент.
В общем, специализированные генераторы шрифтов пока не стали массовым явлением, тогда как универсальные нейросети научились генерировать отдельные буквы и надписи внутри изображений гораздо быстрее и привлекли больше внимания дизайнеров-графиков. Далее мы сосредоточимся именно на этих общих моделях (таких как Midjourney, DALL-E, Stable Diffusion и их преемники вроде Gemini и GPT-5) и том, как они обращаются с буквами различных письменностей.
Понимает ли нейросеть принципы графем и различает аллографы?
Графема – минимальная единица письма (грубо говоря, скелет буквы), а аллографы – различные формы одной буквы (например, заглавная и строчная «Ии», или их болгарский аналог, похожий на латинскую «u»). Встает вопрос: когда нейросеть генерирует текст, есть ли у неё понимание структуры букв? Отличает ли она, скажем, латинскую «u» от болгарской адаптации «и», или знает ли, что строчная g может быть в виде печатного варианта либо рукописного в зависимости от шрифта?

Ренессансная антиква Кирилла Гогова (из книги Васила Йончева «Шрифт в веках»). Источник
В классическом смысле «понимания» у модели нет – у неё нет встроенного знания алфавита, как у человека. Но многое зависит от обучения. Если модель натренирована на изображениях с надписями на разных языках, она может статистически усвоить различия форм букв. Например, современные модели Gemini или GPT-4 Vision обучались на данных, охватывающих десятки языков. Gemini заявлен как поддерживающий множество языков для генерации и редактирования изображений (в том числе русский, английский, китайский и др.). Это значит, что в процессе обучения модель видела подписи и тексты на этих языках и научилась сопоставлять контекст с правильным алфавитом. Проще говоря, если в сгенерированном изображении должен быть русский текст, Gemini, скорее всего, будет рисовать буквы кириллицы, а не латиницы.
Однако на практике до недавнего времени нейросети нередко путали похожие буквы разных алфавитов. Так, тесты пользователей показывали, что модель наподобие DALL-E 3 (2024 г.) при запросе кириллического текста могла перепутать символы «И» и «N», «а» и «е» – то есть на месте русской И нарисовать латинскую N, и наоборот. Причина – визуальное сходство этих букв; не имея глубокого понимания языкового контекста, модель могла брать за основу форму, которая чаще встречалась ей в обучении. Аналогично, если буквы были повернуты или стилизованы, нейросеть могла терять ориентиры: например, при зеркальном отражении буквы добавлялись лишние элементы или хвосты. Отмечались ошибки и в различении шрифтовых стилей: жирная буква и узорная буква могли восприниматься моделью как разные символы. Эти наблюдения сделали сами разработчики, тестируя GPT-4V: им пришлось специально «объяснять» модели отличия, скажем, между кириллической И и латинской N (разница в направлении диагонали и пр.), чтобы улучшить распознавание.
Иными словами, нейросеть может научиться различать алфавиты, но это требует явного обучения на примерах и даже дополнительных подсказок или правил. Новые модели от Google и OpenAI, судя по демонстрациям, успешно пишут не только по-английски, но и по-русски, иероглифами, арабским письмом и т.д. Вероятно, при обучении они использовали сочетание крупной языковой модели (для осознания, какие символы должны быть) и генеративной модели (для рисования формы). Например, модель GPT-4o от OpenAI обучена на объединённом распределении текста и пикселов, что, по словам компании, дало ей «удивительную зрительную насмотренность» – она может генерировать символы, опираясь на внутренние знания языка. Это подразумевает, что если GPT-4 знает слово «Привет» (как последовательность букв), то при генерации картинки с этим словом она стремится изобразить именно П-Р-И-В-Е-Т по порядку, а не набор случайных похожих завитков. Такая интеграция текстового и визуального модулей – значимый шаг вперёд.
Тем не менее, даже самым новым моделям, вероятно, недостаёт настоящего «понимания» шрифта в терминах черт, контуров и начертаний. Они не оперируют понятием «это рукописный аллограф буквы g» или «у кириллической У должен быть такой-то изгиб» – вместо этого они просто выучивают множество образцов и ассоциируют их с соответствующими символами. Можно сказать, нейросеть имитирует знание о графемах. Например, она может воспроизвести печатные латинские буквы с засечками, потому что видела много примеров Times New Roman; но если попросить её нарисовать редкий орнаментальный шрифт, она начнет фантазировать и, возможно, собьётся, показав артефакты. Отсюда – эффект «гибридизации», когда модель смешивает признаки разных, но похожих букв.

Попытка сгенерировать кассу шрифта с помощью модели Flux, январь 2025
Подведём итог: современные нейросети всё лучше различают системы письма, благодаря мульти-языковому обучению. Если в запросе явно указан язык (например, «написать слово по-русски шрифтом таким-то»), передовые модели справляются довольно уверенно. Однако стопроцентной гарантий правильности алфавита пока нет – иногда проскакивают ошибки, особенно с визуально схожими символами. Полноценного осознания структуры шрифта (как набора штрихов, скелета буквы, контрастности и т.п.) у сети нет, она действует статистически. Поэтому и возникают типичные визуальные артефакты AI-текста, которые мы рассмотрим далее. Парадоксально, но именно эти недостатки сегодня привлекают внимание дизайнеров, превращаясь в своеобразный стиль.
Типичные артефакты «нейро-текста» и их типология
Ниже перечислены наиболее характерные визуальные закономерности и искажения, которые можно наблюдать в буквах, сгенерированных нейросетями (особенно предыдущими поколениями моделей вроде Stable Diffusion, Midjourney до v5.2, DALL-E 2/3 и др.). Эти артефакты во многом обусловлены теми самыми ограничениями восприятия текста моделью, о которых говорилось выше. Интересно, что набор ошибок достаточно стабилен – разные модели генерируют текст, похожий неправильно. Фактически сформировалась новая типология артефактов, которую уже можно использовать как своеобразную шпаргалку или даже художественный приём. Перечислим основные пункты.

— Волнообразный внешний контур глифов. Многие ИИ-буквы выглядят словно чуть подтаявшими или дрожащими – их внешний контур идёт неровной волной. Частота и амплитуда этой «волны» могут меняться: от тонкого дрожания линий (как будто написано рукой на дрожащей бумаге) до крупных волн на границах букв, искажающих силуэт. Например, прямая вертикаль буквы «H» может получиться волнистой. Это связано с тем, что диффузионная модель генерирует изображение пиксельно и не придерживается идеально ровных линий, как векторный шрифт. Нейросеть просто пытается повторить общую форму, но мелкие шумы и отсутствие строгих геометрических ограничений приводят к этому волнообразному эффекту.
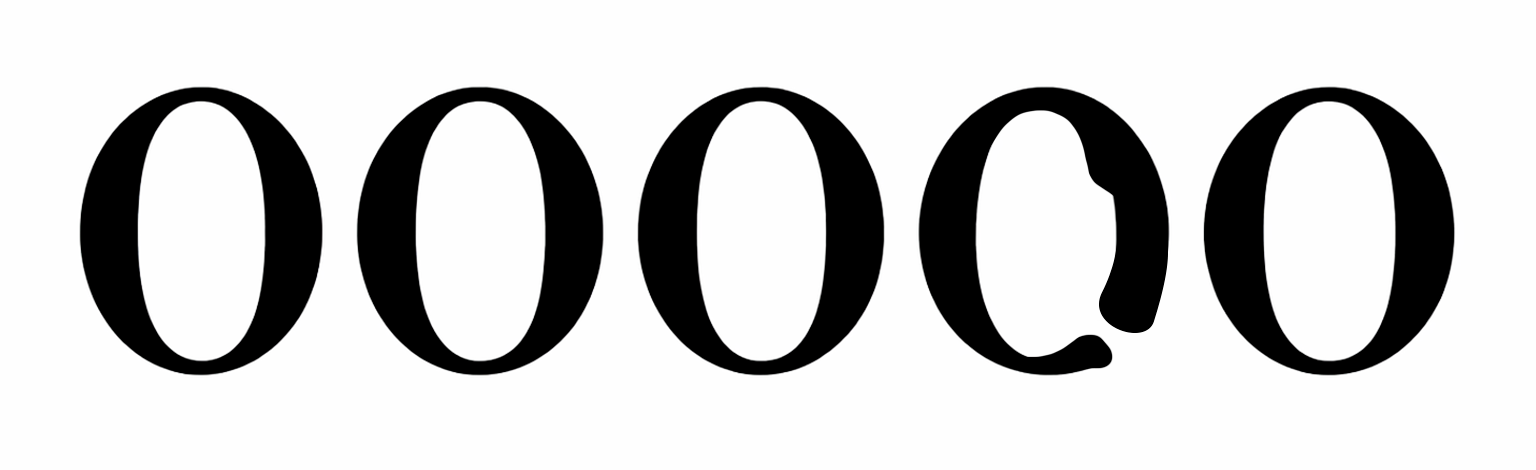
— Локальные утолщения и провалы штриха. Другой частый артефакт – неравномерная толщина линий буквы. В одной части штрих может внезапно утолщаться, а через пару миллиметров – наоборот сужаться или почти пропадать (провал штриха). В традиционном шрифте толщина меняться должна плавно и обоснованно (контраст шрифта), а у ИИ-буквы эти перепады выглядят случайно. Например, округлые части буквы «О» могут иметь внезапный бугорок – локально более толстое место, или дырочку – просвет, куда как будто «не пропечаталась краска». Это наследие работы диффузионной модели: она оптимизирует картинку по местным паттернам и может где-то «решить», что темнее – лучше, а где-то – что светлее, если так случайно получилось в обучающих примерах. В результате штрих теряет равномерность.

— Преобразование терминалов: псевдо-засечки, скругления и шипы. Терминалы – концы основных штрихов букв (например, концы горизонтальной линии у «Т» или завершающие точки дуги «C»). В сгенерированном тексте часто можно заметить, что концам штрихов как будто «не хватает уверенности»: они то обрастают лишними засечками, как небольшими выступами (даже если шрифт предполагался без засечек), то наоборот растворяются и скругляются, как в растёкшейся краске, либо вытягиваются в острие. Например, кончик буквы «S» может внезапно обзавестись маленьким хвостиком, напоминающим засечку, или распасться на несколько тонких линий. Такое происходит из-за того, что модель видела много разных шрифтов – и порой комбинирует их признаки неконтролируемо. Засечки – это вообще отдельная головоломка: ИИ иногда частично их переносит, даже когда они неуместны, либо рисует несимметрично (с одной стороны буквы есть намёк на засечку, с другой нет).

— Искажения внутренних форм (просветов). Почти у каждой буквы есть внутреннее пространство – например, просвет в «О», «А» или полуовал в «Р». В сгенерированных AI буквах эти внутренние формы нестабильны: они могут слишком сжиматься – превращая, скажем, «О» в некое подобие строчной «а» или «U». Бывает, что круглый просвет превращается в острый угол или в амёбную форму. К примеру, буква «A» могла бы получить нехарактерно скругленные углы в антиквенной форме, либо наоборот «P» с неравномерным треугольным штрихом. Опять же, причина – отсутствие у сети строгих правил: идеальная геометрия внутренних пространств не заложена, поэтому они гуляют. Человеку эти искажения сразу заметны, потому что нарушаются пропорции буквы и ухудшается разборчивость.

На некоторых упаковках товаров от Самоката в 2025 году появились заигрывания с гибридизацией и смешиванием форм символов. На обложке альбома «Любовь» певицы Светы буквы очень напоминают эффект ИИ, но в 1999 году нейросетей еще не существовало :)
— Гибридизация похожих букв. Это один из самых любопытных артефактов: нейросеть иногда как будто смешивает две буквы в одну, особенно если они похожи по начертанию. Например, латинские «a» и «e» – оба имеют округлую форму с терминалами сверху и снизу, и ИИ нередко переворачивает или отражает по горизонтали и вертикали эти символы. Получается гибрид a/e. В кириллице также часто смешиваются «э», «є» и «е», или «c» и «e». Иногда ИИ может подставить разные аллографы под традиционную печатную форму. Гибридизация – следствие того, что модель не уверена, какую букву рисовать (особенно если она пытается списать слово из контекста изображения, а не получила явный текст). Тогда она совмещает свойства нескольких вероятных вариантов. Для чтения это катастрофа – мозг видит и то, и другое, не может распознать однозначно. Но визуально такие гибриды выглядят как интересные, хотя и ошибочные, новые формы букв. В 2025 году мода на такие буквы-перевёртыши и гибриды снова вернулась после 20 лет забвения.

— Случайные сдвиги по базовой линии. Обычно в строке текста все буквы стоят ровно на базовой линии (воображаемой горизонтальной черте). У нейросетевых же надписей порой видно, что отдельные буквы проваливаются ниже или приподнимаются выше строки. Например, слово выглядит «скачущим»: одна буква чуть подпрыгнула, другая просела. Этот микросдвиг может быть еле заметным, а может – весьма выраженным, словно буквы разного размера или как будто набраны на неровной поверхности. Откуда это берётся? Вероятно, из-за того, что в обучающих изображениях текст часто представлен на реальных сценах (вывески под углом, надписи на баннерах с перспективой и т.п.), где оптическая линия текста не идеально ровная. Модель перенимает эту вариативность. Для типографики это, конечно, брак – но для нейросети это не очевидно, она не заложила правило «все символы на одном уровне». Впрочем, такой приём часто применяется в акциденции, что также могло быть материалом для обучения.

— Непредсказуемый межбуквенный интервал. Ещё один артефакт – это неравномерный кернинг (пробелы между буквами). ИИ может расположить одни буквы слишком близко (аж до слияния или наложения), а другие – с избыточным разрывом. В результате слово распадается на фрагменты или, наоборот, сливается. Например, между «T» и «Y» может появиться большой разрыв, а между следующими «E» и «F» – внезапно вообще нет пробела. Такие проблемы наблюдались даже у моделей, умеющих писать английские слова: буквы получались разорванными, как будто каждая живёт своей жизнью. Это происходит потому, что нейросеть не оптимизирует текст как единое целое, у неё нет правила равномерного оптического интервала. В обучении она видела надписи с разной плотностью, вот она и не всегда угадывает, каков должен быть идеальный. Для читателя же любое аномальное расстояние сбивает ритм слова.
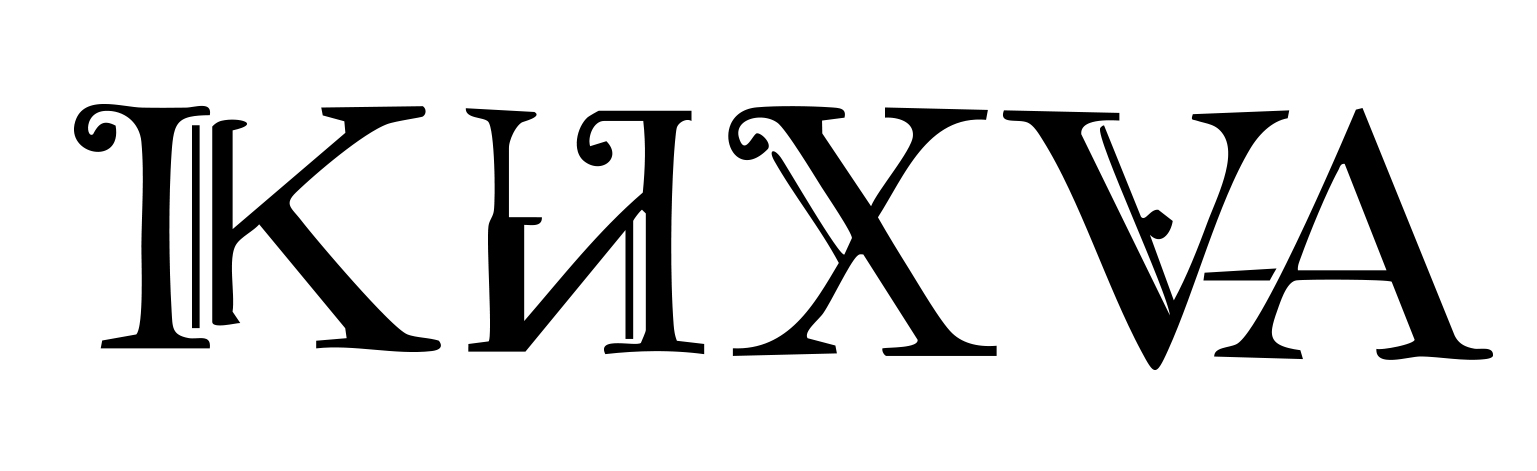
— Разрывы и фрагменты штрихов. Наконец, заметим такой артефакт: некоторые буквы могут оказаться недорисованными или «расслоенными». Например, прямой штрих буквы “l” вдруг прерывается посередине тонким пробелом – будто ручка оторвалась при письме. Или дуга “D” вместо цельной линии состоит из нескольких кусочков, слегка смещённых. Иногда рядом с буквой как бы «теневое» наложение – второй контур, не совмещённый с первым (эффект двоения). Все эти мелкие дефекты – результат того, что генеративный процесс мог сойтись не идеально: алгоритм «denoise» и «fix compression» могли породить лишние артефакты, которые выглядят как разрыв линии, или модель могла наслаивать несколько вариантов. Человек бы провёл цельную черту, а нейросеть может нарисовать её фрагментарно. В итоги мы видим неровности и разрывы контура, нарушающие систему генеративного «шрифта».
Конечно, не каждое AI-изображение текста содержит все перечисленные артефакты сразу. С развитием моделей многие из них сглаживаются: например, DALL-E 3 уже гораздо реже путает кириллицу с латиницей, а Gemini почти не даёт гибридов букв – он пишет ровно то слово, что задано, и шрифт по стилю достаточно цельный. Тем не менее, даже самые новые нейросети не идеальны, и придирчивый глаз шрифтовика всегда выловит какие-то отклонения от типографической нормы.
Важно отметить: эти артефакты стали настолько узнаваемыми, что сформировали особый визуальный язык – эстетику нейро-текста. Подобно тому как шум плёнки или артефакты JPEG когда-то стали стилистическими приёмами, сейчас волнистые буквы или гибридные формы, рождаемые нейросетью, можно рассматривать как художественный эффект. Причём эффект эксклюзивный для нашего времени: такое сочетание «ошибок» могло появиться только при работе AI. «Нейро-текст» стал маркером эпохи, показателем, что изображение сгенерировано именно во время зарождающегося нейро-дизайна 2020-х.
От ошибки к стилю: использование артефактов в дизайне
Раз уж артефакты нейросетевой генерации текста обладают ярко выраженным характером, возникает заманчивая идея: побороть их не устранением, а принятием, превратив недостатки в стиль хотя бы в некоторых сценариях. Для графических дизайнеров и шрифтовых дизайнеров это открывает новое направление творчества – использование типичных AI-искажений как художественных приёмов. Рассмотрим несколько подходов, как можно интегрировать нейросетевые артефакты в осмысленный дизайн.
— Типология артефактов как дизайн-материал. Прежде всего, перечисленные выше искажения можно осознанно каталогизировать и применить для придания работе нужного настроения. К примеру, если мы хотим создать постер, который сразу ассоциируется с ИИ-эстетикой, мы можем нарочно внести элементы «дрожащего контура» или гибридных букв. Зная, какие особенности свойственны нейротексту, дизайнер как бы использует их как палитру эффектов. Это похоже на то, как glitch-art художники намеренно вносят цифровые помехи, чтобы получить характерный облик изображения. Так и здесь: волну вдоль контуров, случайные засечки, провалы штрихов – всё это можно добавить в буквы специально, имитируя технологичность или вызывая ассоциации с роботами, будущим, киберпанком. В результате текст будет выглядеть слегка неправильным, вызывая у зрителя ощущение «сгенерированности», но при этом оставаясь под контролем дизайнера.
Кроме того, макеты с такими асистемными символами существовали со времен возникновения письменности. Люди, которые не знакомы с принципами формообразования глифов, писали их порой как вздумается. Присмотритесь к уличным утилитарным надписям на дверях мелких мастерских, почтовых ящиках или заборах во время прогулки — «Ремонт обуви», «Машины не парковать!», «Почта» и т.д. Без трафарета люди часто допускают ошибки в конструкции, подобно слабо обученным нейросетям — где-то кривая «у», где-то «т» похожа на «m». Некоторые исследователи и энтузиасты видят в таких «ошибках» свой особенный шарм, «остроту» и стиль.

Hand-made указатель на базе отдыха «Динамо» в Анапе, февраль 2025
— Превращение ошибки в стиль. Каждое отдельное искажение можно переосмыслить как черту стиля шрифта. Например, возьмём артефакт гибридизации a/e. Вместо того чтобы считать это ошибкой, можно разработать намеренно гибридные глифы, которые объединяют формы двух букв. В дизайнерском проекте такая буква будет выглядеть как художественный прием, упрощая систему шрифта или даже символизируя двусмысленность. Или рассмотрим волнистый контур: если придать всем буквам шрифта аккуратную синусоидальную волну по краям, получится стиль, напоминающий «живой» или «текучий» шрифт, колеблющийся как желе. В цифровом шрифтовом дизайне есть понятие variable Font axes – переменные параметры шрифта. Можно представить себе ось вариативности «волнения контура», где 0 – ровно, а 100 – сильная волна. Тогда дизайнер мог бы управлять степенью этого эффекта. Аналогично, можно ввести ось «Casual», как в шрифте Recursive, где при увеличении значения буквы меняют плавность терминалов и наплывов от более рационального Linear к более дружелюбному/энергичному Casual (меняются кривизна, терминалы, немного контраста). Таким образом, то, что у ИИ было бы неконтролируемым дефектом, в руках дизайнера становится контролируемым стилевым параметром.

— Техническая реализация: альтернативы и контекстуальные замены. Шрифтовые технологии OpenType позволяют заложить в гарнитуру несколько начертаний для одной буквы (так называемые стилистические альтернативы) и правила выбора форм в зависимости от контекста. Это идеально подходит для воссоздания хаотичности нейротекста. Например, можно нарисовать для букв несколько вариантов с разными артефактами: вариант «E» с лишней засечкой, вариант с просевшим средним штрихом, вариант с нормальной формой. Затем с помощью контекстуальных альтернатив задать правило: каждой новой «E» в тексте случайным образом присваивается одна из доступных форм. В результате при наборе словами буква «E» будет каждый раз немного отличаться – где-то «недопрописана», где-то с хвостиком – так же, как у нейросети буквы получаются не идентичны друг другу. Похожим образом можно реализовать и различия в просветах: делать для буквы «О» несколько версий с разным внутренним овалом и рандомно их чередовать. Благодаря этому текст, набранный уже ручным (точнее, человеческим) шрифтом, начнёт выглядеть «как сгенерированный». Такой «вариативный нейро-шрифт» мог бы стать интересным экспериментом: контроль за дизайнером, но впечатление хаотичности присутствует. Есть шрифты, которые заигрывают с такой эстетикой и без сложных OpenType фич. Например, acogessic от Стефана Ванли, созданный в конце 00-х, сегодня ощущается как что-то генеративное и выглядит очень необычно:

Комбинирование с нейросетями в дизайне. Конечно, никто не мешает дизайнерам и прямо использовать нейросети, принимая их артефакты как часть композиции. Например, можно сгенерировать нейросетью заголовок с заведомо «глючным» текстом, а затем доработать его вручную: где надо – чуть подчистить, но самые интересные «ошибки» оставить. Такая техника уже применяется в коммуникационном дизайне, когда нужно придать работе особый стиль. В итоге получается гибрид ручного и машинного: нейросеть дала исходный материал с его уникальными особенностями, а дизайнер адаптировал под цели и задачи композиции.

Нашумевшая работа дизайнера vanök regular 🍏 для Glukoza. В айдентике музыкального альбома использовался ИИ для вдохновения и поиска той самой нейро-эстетики
Пока что применение нейро-текста как стиля находится на экспериментальной стадии. Но уже можно предположить, что через годы это станет ретро-трендом: будущие дизайнеры, имея безупречные алгоритмы генерации, возможно, нарочно будут эмулировать «глючный» ИИ-текст 2020-х – как сегодня мы эмулируем шум видеокассеты или артефакты старых цифровых камер, чтобы придать изображению особый характер. Поэтому фиксация типологии артефактов (как в этой статье) – не только аналитический шаг, но и потенциально база для будущих стилизаций и исследований.
Можно ли научить нейросеть писать идеально – и нужны ли нам идеальные буквы?
Главный исследовательский вопрос – способны ли будущие модели полностью избавиться от перечисленных артефактов и генерировать текст не хуже профессионального шрифтового дизайна? Судя по нынешним темпам прогресса, ответ близок к «да». Уже сейчас топовые модели (Gemini, GPT-1.5 High и др.) показывают почти безупречные результаты в латинице: они могут создать логотип с аккуратным шрифтом, надпись на вывеске, иллюстрацию с подписью – и текст будет выглядеть убедительно. OpenAI прямо заявляет, что встроенная в GPT-4 генерация изображений превратила их ИИ в «полезный инструмент визуальной коммуникации», где можно создавать именно тот образ и ту надпись, которые задуманы. Google также подчёркивает «студийное качество контроля над изображением» в Gemini и способность точно визуализировать задуманное, включая текст.
Однако достичь идеала типографского качества – значит, наделить нейросеть полноценными знаниями о шрифтах или интегрировать в неё внешние алгоритмы, которые будут отвечать за буквы. Возможные направления улучшений, о которых говорят эксперты , включают:
— Встраивание механизмов оптического распознавания символов (OCR) в контур генерации. Если генератор на лету будет “читать” собственный выход и сверяться с тем, что должно быть написано, он сможет корректировать ошибки. Например, сгенерировал слово – параллельная OCR-модель прочла и сказала: это не «Hello», а «Hcℓlo», поправь. Такая обратная связь могла бы устранить нелепицы вроде гибридных или пропавших букв. OCR-модели уже применяются различными нейросетями, но, конечно, не для всех языков.
— Разметка и фильтрация обучающих данных. Если собрать специальный датасет изображений с текстом, где текст чётко размечен, и обучить модель генерировать именно такие изображения (например, тысячи плакатов с известными шрифтами и словами), то качество генерации текста будет выше. Добавление в обучение ещё большего числа примеров надписей явно улучшит навыки написания. Также можно повысить долю различных языков, чтобы сеть чётче разделяла алфавиты.
— Специализированные архитектуры. Возможно, появятся гибридные модели, где диффузионный генератор отвечает за фон и изображение, а когда дело доходит до текста, управление передаётся специальному модулю, генерирующему буквы (например, на основе векторных контуров или заранее встроенных шрифтов). Уже сейчас дизайнеры практикуют такой подход вручную: генерируют картинку без текста, а затем добавляют текст классическим способом (векторным шрифтом), либо используют нейросеть для замены «кривого» текста на более ровный (как предлагает Canva Magic и др.). В будущем модель может сама проделывать подобное: сначала рисует сцену, потом «понимает», что здесь должен быть текст, и рисует его по-другому алгоритму – вплоть до ровных кривых.
— Учёт правил письма и типографики. Например, задать в функции потерь жёсткие штрафы за нечитабельность: если внутренний OCR не распознал слово – перегенерировать. Либо добавлять «знания» о метриках шрифта (про baseline, x-height и т.д.) так, чтобы модель генерировала буквы, подчиняющиеся типографическим правилам. Это сложная задача, но в рамках обучения с подкреплением или пост-обучения вполне реальная.
Скорее всего, через несколько месяцев/лет мы действительно получим модели, у которых перечисленные в этой статье артефакты будут сведены к минимуму. Нейросеть научится писать «как надо» – и волнистые линии или странные гибриды останутся в прошлом. Стремясь к этому, разработчики решают практическую задачу: убрать барьер для использования ИИ в дизайне. Когда нейросеть генерирует текст без ошибок, её можно прямо внедрить в рабочий конвейер (например, в тот же Figma или Photoshop) без опасений, что придётся всё перепечатывать вручную.
Интересно, что исчезновение артефактов поставит новый вопрос: как тогда относиться к старым визуальным идеям, рождённым благодаря ошибкам? Вероятно, они перекочуют в разряд стилизованных эффектов. То есть будущие инструменты, возможно, позволят включать «режим нейро-текста» искусственно – для придания дизайну атмосферы 2020-х. Ведь, как отмечалось, нейро-текст уже стал культурным феноменом.
С практической точки зрения, шрифтовым дизайнерам не стоит бояться совершенствования ИИ: идеальный генератор текста не отменяет ручного творчества, а лишь берёт на себя рутинную часть. Да, пропадёт элемент непреднамеренной случайности, но зато появится возможность использовать ИИ как умный инструмент: задал слово и стиль – получил сразу качественную надпись, которую можно включать в макет. А тем, кто ценит художественный беспорядок нейросетевых артефактов, всегда останется возможность творчески его эмулировать. Как мы обсудили, средствами вариативных шрифтов или фильтров можно воспроизвести любой из сегодняшних дефектов – только уже в осознанной дозировке.
Заключение
Генеративные нейросети привнесли в область типографики и дизайна новую волну идей. С одной стороны, они поставили задачу – научить машину писать так же чётко, как человек. Этот путь уже близок к цели: передовые модели демонстрируют способность генерировать аккуратный многоязычный текст внутри изображений, и можно ожидать, что вскоре проблема «каракулей вместо букв» канет в лету. С другой стороны, парадоксальным образом именно несовершенство первых нейросетей породило уникальный визуальный стиль – ту самую смесь полу-букв, артефактов и странных форм, которую мы назвали нейро-текстом. Для дизайнеров он стал новым источником формообразования: то, что вчера считалось ошибкой алгоритма, сегодня превращается в вдохновение для эклектичного шрифта или авангардного плаката.
Мы рассмотрели основные типы артефактов AI-генерации букв – волнистые контуры, нестабильные штрихи, гибридные глифы и прочие – и показали, как каждый из них может быть трансформирован в преднамеренный стилистический приём. Освоение этой типологии полезно как шрифтовым дизайнерам, так и коммуникационным дизайнерам, работающим с генерируемыми изображениями (чтобы понимать природу артефактов и использовать их креативно, а не бояться их).
Нейросетевые шрифты, безусловно, находятся ещё в ранней стадии развития. Но уже сейчас ясно, что их влияние двояко: с одной стороны, они автоматизируют и ускоряют привычные процессы (создать надпись, набросать стилистику шрифта), с другой – они расширяют само понятие шрифта, вводя нас в мир форм, ранее невиданных, но рождённых как побочный продукт алгоритма. Баланс между машинной точностью и машинным же шумом – вот что делает эту тему особенно увлекательной. Возможно, в недалёком будущем мы будем оглядываться на первые AI-надписи так же, как сейчас на пиксельные шрифты 1980-х: с ностальгией, улыбкой и желанием иногда воссоздать ту неровную магию уже нарочно.





![Ар[т]хив: «Made in USA» как явление в графическом дизайне](https://static.insales-cdn.com/r/916HKz7lW0Q/rs:fit:275:0:1/q:100/plain/images/articles/1/2089/13346857/large_ewqgaweg.jpg@jpg)



